Šlo o jeden z těch předmětů, které mi nepřinesly jen znalosti „na zkoušku“, ale trvalé dovednosti pro další práci. Vstupovala jsem do něj s předchozími zkušenostmi z datové žurnalistiky a analýz, takže některé nástroje a principy pro mě nebyly nové. I přesto jsem si z kurzu odnesla spoustu nových praktických dovedností, které jsem rovnou začala využívat v profesní praxi – například práci s dashboardy v Power BI nebo propracovanější přístupy ke standardizaci indexů a tvorbě vizualizací.
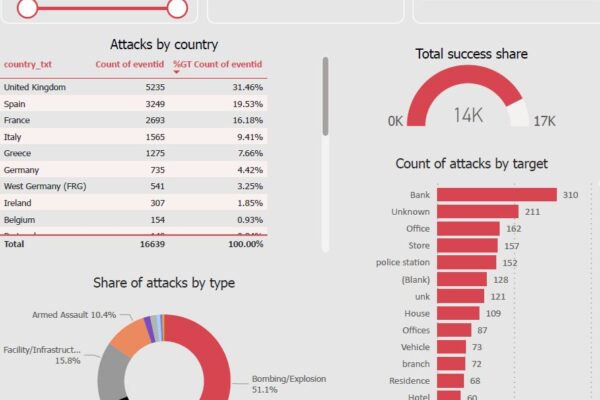
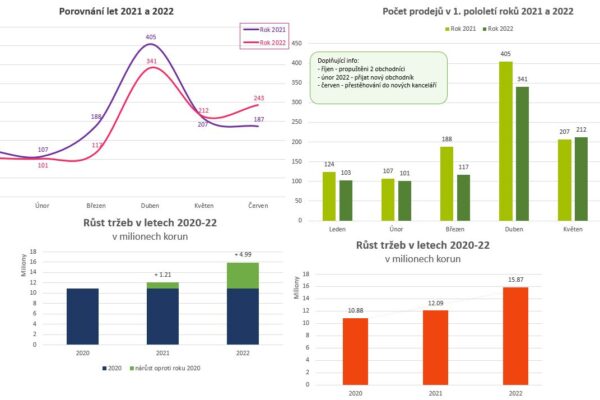
Hlavní přínos pro mě byl ve schopnosti efektivně kombinovat různé datové zdroje, čistit rozsáhlé datasety (např. z volby.cz), vytvářet pokročilejší výpočty ve velkých tabulkách (včetně kontingenčních tabulek a vlastních indexů), a to vše s důrazem na srozumitelné výstupy. Předmět mě přiměl přemýšlet systematicky – od práce se surovými daty až po výslednou interpretaci. V tom se ukázalo, jak důležité je vědět nejen jak, ale i proč určitý krok v analytice dělám.
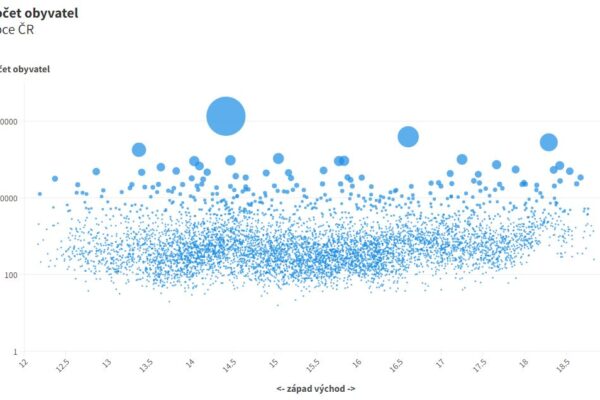
V závěrečném projektu jsem si zvolila netradiční otázku: Jaké je nejprůměrnější město v ČR? Snažila jsem se ukázat, že i s veřejně dostupnými daty lze vytvořit hlubokou a zároveň srozumitelnou analýzu, která má přesah – ať už směrem ke společenské debatě, novinářské práci nebo vzdělávání. Projekt mě bavil nejen obsahově, ale i po technické stránce – testovala jsem různé vizualizační nástroje, kombinovala Google Sheets, Excel, Flourish a Power BI, a promýšlela metody výpočtu tak, aby byly zároveň transparentní i interpretovatelné.
Zpětně vnímám jako nejcennější právě to, že jsem měla možnost skloubit své dosavadní dovednosti s novými přístupy. Navíc mě kurz motivoval, abych se dál vzdělávala v oblasti datových nástrojů – např. se chci více ponořit do Pythonu pro případné opakované zpracování velkých datasetů. I díky tomuto kurzu cítím větší jistotu v analytickém uvažování i v prezentaci výsledků.